Summary of Methods to Protect Archive Log Tapes
I have a client who is concerned about losing archive logs in between full RMAN database and archive log backups, in the event of a loss. I was asked to provide options which I am sharing on this blog. The environment is AIX 6.5 and Oracle 11.2 Standard Edition. Please feel free to comment and share your suggestions.
Options to protect archive log tapes (and the full database) are:
I. Have RMAN take more frequent backups, including archive logs.
II. Oracle allows specification of an alternate destination for archive
logging that is additional to the primary destination.
So, NFS mount a directory on a remote server and use an alternate
“archive_log_dest_1” parameter to specify the NFS mounted remote
directory as the alternate log destination.
III. SFTP or rsynch a copy of the archive logs to a remote server through
a shell script. The shell script would have to:
1. check the V$ARCHIVED_LOG view to determine if each archive log
file in the archive log directory has completed the archiving
process
2. use the rsynch command, or SFTP, to synchronize the remote
archive log destination with the primary server archive log
destination
3. run this script every "nn" time intervals, leaving a window for
the RMAN backups
IV. Use the pre-RMAN method of database backup. Copy the database user
datafiles, control files, archive logs and parameter file to a
directory on a remote server. This requires that an Oracle instance is
installed on the remote server to recover the database from these
files.
V. Use RMAN to rig a standby database, instead of using DataGuard or
GoldenGate. This involves another Oracle instance running on the
remote server, use of RMAN to clone the primary database, shipping
primary database RMAN backup files to a remote server and, finally,
running an RMAN recovery of the database on the remote server.
VI. Create an Oracle RAC 2-node cluster with one cluster being on a
remote server. I believe that this is possible with even Oracle 11.2
Standard Edition, possibly with a relatively small license charge per
node.
I recommended option “III” because it would not require another instance of Oracle on the remote server and it would not slow down the log writer Oracle process (LGWR) which would most likely result in a general database slowdown. In addition, the server OS/network resources used, if the script is not run very excessively, should not be sufficient to slowdown the Oracle database or the application. My suggestion is to determine the average amount of time that the database takes to fully archive a log, decide how many logs you would like copied at the same time and use that average as a guideline to determine how frequently to schedule the script.
Sunday, May 8, 2011
Thursday, January 27, 2011
ORACLE 11g HEALTH CHECK MONITOR
The Oracle Health Check Monitor (HM) facility is new with Oracle 11.1 database. It can run diagnostic checks that detect:
> file corruptions – reports failures if these files are inaccessible, corrupt or inconsistent. If the database is in mount or open mode, this check examines the log files and data files listed in the control file. If the database is in NOMOUNT mode, only the control file is checked.
> physical and logical block corruptions – detects disk image block corruptions such as checksum failures, head/tail mismatch, and logical inconsistencies within the block. Most corruptions can be repaired using Block Media Recovery. Corrupted block information is also captured in the V$DATABASE_BLOCK_CORRUPTION view. This check does not detect inter-block or inter-segment corruption.
> undo and redo corruptions -
For redo, HM scans the contents of the redo log for accessibility and corruption, as well as the archive logs, if available. The Redo Integrity Check reports failures such as archive log or redo corruption.
For undo, HM finds logical undo corruptions. After locating an undo corruption, this check uses PMON and SMON to try to recover the corrupted transaction. If this recovery fails, then Health Monitor stores information about the corruption in V$CORRUPT_XID_LIST. Most undo corruptions can be resolved by forcing a commit.
> transaction integrity check – identical to the Undo Segment Integrity Check except that it checks only one
specific transaction
> data dictionary corruptions – examines the integrity of core dictionary objects, such as tab$ and col$. It performs the following operations:
*
o Verifies the contents of dictionary entries for each dictionary object.
o Performs a cross-row level check, which verifies that logical constraints on rows in the dictionary are enforced.
o Performs an object relationship check, which verifies that parent-child relationships between dictionary objects are enforced.
The Dictionary Integrity Check operates on the following dictionary objects:
tab$, clu$, fet$, uet$, seg$, undo$, ts$, file$, obj$, ind$, icol$, col$, user$, con$, cdef$, ccol$, bootstrap$, objauth$, ugroup$, tsq$, syn$, view$, typed_view$, superobj$, seq$, lob$, coltype$, subcoltype$, ntab$, refcon$, opqtype$, dependency$, access$, viewcon$, icoldep$, dual$, sysauth$, objpriv$, defrole$, and ecol$.
Each of the above checks can be used with parameters that provide specific subcategories of information.
Run HM Checker Manually
The Oracle Health Monitor (HM) can be run using the following syntax manually:
BEGIN
DBMS_HM.RUN_CHECK(‘type of check’, ‘name of HM check run’);
END;
Example:
SQL>
BEGIN
DBMS_HM.RUN_CHECK(‘Data Block Integrity Check’, ‘db_blk_integ_run’);
END;
SQL> /
The types of checks that can be obtained in this manner (in place of ‘type of check’ above) are:
HM Test Check
DB Structure Integrity Check
CF Block Integrity Check
Data Block Integrity Check
Redo Integrity Check
Logical Block Check
Transaction Integrity Check
Undo Segment Integrity Check
No Mount CF Check
Mount CF Check
CF Member Check
All Datafiles Check
Single Datafile Check
Tablespace Check Check
Log Group Check
Log Group Member Check
Archived Log Check
Redo Revalidation Check
IO Revalidation Check
Block IO Revalidation Check
Txn Revalidation Check
Failure Simulation Check
Dictionary Integrity Check
ASM Mount Check
ASM Allocation Check
ASM Disk Visibility Check
ASM File Busy Check
Most health checks accept input parameters. You can view parameter names and descriptions with the V$HM_CHECK_PARAM view. Some parameters are mandatory while others are optional. If optional parameters are omitted, defaults are used. The following query displays parameter information for all health checks:
SELECT c.name check_name, p.name parameter_name, p.type,
p.default_value, p.description
FROM v$hm_check_param p, v$hm_check c
WHERE p.check_id = c.id and c.internal_check = ‘N’
ORDER BY c.name;
Input parameters are passed in the input_params argument as name/value pairs separated by semicolons (;). The following example illustrates how to pass the transaction ID as a parameter to the Transaction Integrity Check:
BEGIN
DBMS_HM.RUN_CHECK (
check_name => ‘Transaction Integrity Check’,
run_name => ‘my_run’,
input_params => ‘TXN_ID=7.33.2′);
END;
Running HM Checker using Enterprise Manager:
1. On the Database Home page, in the Related Links section, click Advisor Central.
2. Click Checkers to view the Checkers subpage.
3. In the Checkers section, click the checker you want to run.
4. Enter values for input parameters or, for optional parameters, leave them blank to accept the defaults.
5. Click Run, confirm your parameters, and click Run again.
Viewing HM Checker Reports
You can now view a report of a checker execution. The report contains findings, recommendations, and other information. You can view reports using Enterprise Manager, the ADRCI utility, or the DBMS_HM PL/SQL package. The following table indicates the report formats available with each viewing method.
Report Viewing Method Report Formats Available
Enterprise Manager HTML
DBMS_HM PL/SQL package HTML, XML, and text
ADRCI utility XML
To view run findings using Enterprise Manager
1. Access the Database Home page.
2. In the Related Links section, click Advisor Central.
3. Click Checkers to view the Checkers subpage.
4. Click the run name for the checker run that you want to view.
The Run Detail page appears, showing the findings for that checker run.
1. Click Runs to display the Runs subpage.
Enterprise Manager displays more information about the checker run.
1. Click View Report to view the report for the checker run.
The report is displayed in a new browser window.
Viewing Reports Using DBMS_HM
You can view Health Monitor checker reports with the DBMS_HM package function GET_RUN_REPORT. This function enables you to request HTML, XML, or text formatting. The default format is text, as shown in the following SQL*Plus example:
SET LONG 100000
SET LONGCHUNKSIZE 1000
SET PAGESIZE 1000
SET LINESIZE 512
SELECT DBMS_HM.GET_RUN_REPORT(‘HM_RUN_1061′) FROM DUAL;
DBMS_HM.GET_RUN_REPORT(‘HM_RUN_1061′)
———————————————————————–
Run Name : HM_RUN_1061
Run Id : 1061
Check Name : Data Block Integrity Check
Mode : REACTIVE
Status : COMPLETED
Start Time : 2011-01-12 22:11:02.032292 -07:00
End Time : 2011-01-12 22:11:20.835135 -07:00
Error Encountered : 0
Source Incident Id : 7418
Number of Incidents Created : 0
Input Paramters for the Run
BLC_DF_NUM=1
BLC_BL_NUM=64349
Run Findings And Recommendations
Finding
Finding Name : Media Block Corruption
Finding ID : 1065
Type : FAILURE
Status : OPEN
Priority : HIGH
Message : Block 64349 in datafile 1:
‘/ade/sfogel_emdb/oracle/dbs/t_db1.f’ is media corrupt
Message : Object BMRTEST1 owned by SYS might be unavailable
Finding
Finding Name : Media Block Corruption
Finding ID : 1071
Type : FAILURE
Status : OPEN
Priority : HIGH
Message : Block 64351 in datafile 1:
‘/ade/sfogel_emdb/oracle/dbs/t_db1.f’ is media corrupt
Message : Object BMRTEST2 owned by SYS might be unavailable
Viewing Reports Using the ADRCI Utility
You can create and view Health Monitor checker reports using the ADRCI utility.
To create and view a checker report using ADRCI
1. Ensure that operating system environment variables (such as ORACLE_HOME) are set properly, and then enter the following command at the operating system command prompt:
2. ADRCI
The utility starts and displays the following prompt:
adrci>>
Optionally, you can change the current ADR home. Use the SHOW HOMES command to list all ADR homes, and the SET HOMEPATH command to change the current ADR home. See Oracle Database Utilities for more information.
3. Enter the following command:
show hm_run
This command lists all the checker runs (stored in V$HM_RUN) registered in the ADR repository.
4. Locate the checker run for which you want to create a report and note the checker run name. The REPORT_FILE field contains a filename if a report already exists for this checker run. Otherwise, generate the report with the following command:
5. create report hm_run run_name
6. To view the report, enter the following command:
show report hm_run run_name
** For more details regarding HM views, parameters and more see
http://download.oracle.com/docs/cd/B28359_01/server.111/b28310/diag007.htm
*** Reference Oracle® Database Administrator’s Guide 11g Release 1 (11.1)
Part Number B28310-04
The Oracle Health Check Monitor (HM) facility is new with Oracle 11.1 database. It can run diagnostic checks that detect:
> file corruptions – reports failures if these files are inaccessible, corrupt or inconsistent. If the database is in mount or open mode, this check examines the log files and data files listed in the control file. If the database is in NOMOUNT mode, only the control file is checked.
> physical and logical block corruptions – detects disk image block corruptions such as checksum failures, head/tail mismatch, and logical inconsistencies within the block. Most corruptions can be repaired using Block Media Recovery. Corrupted block information is also captured in the V$DATABASE_BLOCK_CORRUPTION view. This check does not detect inter-block or inter-segment corruption.
> undo and redo corruptions -
For redo, HM scans the contents of the redo log for accessibility and corruption, as well as the archive logs, if available. The Redo Integrity Check reports failures such as archive log or redo corruption.
For undo, HM finds logical undo corruptions. After locating an undo corruption, this check uses PMON and SMON to try to recover the corrupted transaction. If this recovery fails, then Health Monitor stores information about the corruption in V$CORRUPT_XID_LIST. Most undo corruptions can be resolved by forcing a commit.
> transaction integrity check – identical to the Undo Segment Integrity Check except that it checks only one
specific transaction
> data dictionary corruptions – examines the integrity of core dictionary objects, such as tab$ and col$. It performs the following operations:
*
o Verifies the contents of dictionary entries for each dictionary object.
o Performs a cross-row level check, which verifies that logical constraints on rows in the dictionary are enforced.
o Performs an object relationship check, which verifies that parent-child relationships between dictionary objects are enforced.
The Dictionary Integrity Check operates on the following dictionary objects:
tab$, clu$, fet$, uet$, seg$, undo$, ts$, file$, obj$, ind$, icol$, col$, user$, con$, cdef$, ccol$, bootstrap$, objauth$, ugroup$, tsq$, syn$, view$, typed_view$, superobj$, seq$, lob$, coltype$, subcoltype$, ntab$, refcon$, opqtype$, dependency$, access$, viewcon$, icoldep$, dual$, sysauth$, objpriv$, defrole$, and ecol$.
Each of the above checks can be used with parameters that provide specific subcategories of information.
Run HM Checker Manually
The Oracle Health Monitor (HM) can be run using the following syntax manually:
BEGIN
DBMS_HM.RUN_CHECK(‘type of check’, ‘name of HM check run’);
END;
Example:
SQL>
BEGIN
DBMS_HM.RUN_CHECK(‘Data Block Integrity Check’, ‘db_blk_integ_run’);
END;
SQL> /
The types of checks that can be obtained in this manner (in place of ‘type of check’ above) are:
HM Test Check
DB Structure Integrity Check
CF Block Integrity Check
Data Block Integrity Check
Redo Integrity Check
Logical Block Check
Transaction Integrity Check
Undo Segment Integrity Check
No Mount CF Check
Mount CF Check
CF Member Check
All Datafiles Check
Single Datafile Check
Tablespace Check Check
Log Group Check
Log Group Member Check
Archived Log Check
Redo Revalidation Check
IO Revalidation Check
Block IO Revalidation Check
Txn Revalidation Check
Failure Simulation Check
Dictionary Integrity Check
ASM Mount Check
ASM Allocation Check
ASM Disk Visibility Check
ASM File Busy Check
Most health checks accept input parameters. You can view parameter names and descriptions with the V$HM_CHECK_PARAM view. Some parameters are mandatory while others are optional. If optional parameters are omitted, defaults are used. The following query displays parameter information for all health checks:
SELECT c.name check_name, p.name parameter_name, p.type,
p.default_value, p.description
FROM v$hm_check_param p, v$hm_check c
WHERE p.check_id = c.id and c.internal_check = ‘N’
ORDER BY c.name;
Input parameters are passed in the input_params argument as name/value pairs separated by semicolons (;). The following example illustrates how to pass the transaction ID as a parameter to the Transaction Integrity Check:
BEGIN
DBMS_HM.RUN_CHECK (
check_name => ‘Transaction Integrity Check’,
run_name => ‘my_run’,
input_params => ‘TXN_ID=7.33.2′);
END;
Running HM Checker using Enterprise Manager:
1. On the Database Home page, in the Related Links section, click Advisor Central.
2. Click Checkers to view the Checkers subpage.
3. In the Checkers section, click the checker you want to run.
4. Enter values for input parameters or, for optional parameters, leave them blank to accept the defaults.
5. Click Run, confirm your parameters, and click Run again.
Viewing HM Checker Reports
You can now view a report of a checker execution. The report contains findings, recommendations, and other information. You can view reports using Enterprise Manager, the ADRCI utility, or the DBMS_HM PL/SQL package. The following table indicates the report formats available with each viewing method.
Report Viewing Method Report Formats Available
Enterprise Manager HTML
DBMS_HM PL/SQL package HTML, XML, and text
ADRCI utility XML
To view run findings using Enterprise Manager
1. Access the Database Home page.
2. In the Related Links section, click Advisor Central.
3. Click Checkers to view the Checkers subpage.
4. Click the run name for the checker run that you want to view.
The Run Detail page appears, showing the findings for that checker run.
1. Click Runs to display the Runs subpage.
Enterprise Manager displays more information about the checker run.
1. Click View Report to view the report for the checker run.
The report is displayed in a new browser window.
Viewing Reports Using DBMS_HM
You can view Health Monitor checker reports with the DBMS_HM package function GET_RUN_REPORT. This function enables you to request HTML, XML, or text formatting. The default format is text, as shown in the following SQL*Plus example:
SET LONG 100000
SET LONGCHUNKSIZE 1000
SET PAGESIZE 1000
SET LINESIZE 512
SELECT DBMS_HM.GET_RUN_REPORT(‘HM_RUN_1061′) FROM DUAL;
DBMS_HM.GET_RUN_REPORT(‘HM_RUN_1061′)
———————————————————————–
Run Name : HM_RUN_1061
Run Id : 1061
Check Name : Data Block Integrity Check
Mode : REACTIVE
Status : COMPLETED
Start Time : 2011-01-12 22:11:02.032292 -07:00
End Time : 2011-01-12 22:11:20.835135 -07:00
Error Encountered : 0
Source Incident Id : 7418
Number of Incidents Created : 0
Input Paramters for the Run
BLC_DF_NUM=1
BLC_BL_NUM=64349
Run Findings And Recommendations
Finding
Finding Name : Media Block Corruption
Finding ID : 1065
Type : FAILURE
Status : OPEN
Priority : HIGH
Message : Block 64349 in datafile 1:
‘/ade/sfogel_emdb/oracle/dbs/t_db1.f’ is media corrupt
Message : Object BMRTEST1 owned by SYS might be unavailable
Finding
Finding Name : Media Block Corruption
Finding ID : 1071
Type : FAILURE
Status : OPEN
Priority : HIGH
Message : Block 64351 in datafile 1:
‘/ade/sfogel_emdb/oracle/dbs/t_db1.f’ is media corrupt
Message : Object BMRTEST2 owned by SYS might be unavailable
Viewing Reports Using the ADRCI Utility
You can create and view Health Monitor checker reports using the ADRCI utility.
To create and view a checker report using ADRCI
1. Ensure that operating system environment variables (such as ORACLE_HOME) are set properly, and then enter the following command at the operating system command prompt:
2. ADRCI
The utility starts and displays the following prompt:
adrci>>
Optionally, you can change the current ADR home. Use the SHOW HOMES command to list all ADR homes, and the SET HOMEPATH command to change the current ADR home. See Oracle Database Utilities for more information.
3. Enter the following command:
show hm_run
This command lists all the checker runs (stored in V$HM_RUN) registered in the ADR repository.
4. Locate the checker run for which you want to create a report and note the checker run name. The REPORT_FILE field contains a filename if a report already exists for this checker run. Otherwise, generate the report with the following command:
5. create report hm_run run_name
6. To view the report, enter the following command:
show report hm_run run_name
** For more details regarding HM views, parameters and more see
http://download.oracle.com/docs/cd/B28359_01/server.111/b28310/diag007.htm
*** Reference Oracle® Database Administrator’s Guide 11g Release 1 (11.1)
Part Number B28310-04
Thursday, January 6, 2011
Oracle GoldenGate and Compressed Tables
OGG does not support compressed tables or partitions, neither does it handle it well with proper error messages until OGG v10.4. The abends may or may not produce any error message and sometimes produce wrong messages.
From V11.1.1.0.0, Oracle has enhanced the error handling part in BugDB 9425542, which gives meaningful error message on the compressed record before Extract abend. It will list out the table name, rowid, etc
Example :
ERROR OGG-01028 Record on table QATEST1.TAB1 with rowid AAM4EkAAEAACBguAAA from transaction 5.24.270123 (0x0005.018.00041f2b) is compressed. Compression is not supported.
However, due to bug 10063108, sometimes the error message on compressed tables are not entirely correct. This problem has been fixed in 11.1.1.0.3 and above
A table created as compressed will cause all of the DML’s to go into compressed blocks on disk. If the user does an "alter table nocompress", every DML that goes into the table AFTER that point in time will be uncompressed. The query for compression will return "nocompress" now, but the simple "alter" does not change the already existing compressed blocks on disk that were created before the "alter". So to capture the records from a table which was compressed we need to do the following
SQL> alter table move nocompress;
This will touch every single block on disk and will uncompress everything thereby causing OGG to work properly and not abend.
If there is even a single partition in a partitioned table that is compressed, it will cause an abend. Partition compression can be verified by getting the full DDL for the table by running the DBMS_METADATA.GET_DDL package. For table partitions that are compressed, run the below query and get the partition names & tablespace names.
SQL> SELECT partition_name, subpartition_name, tablespace_name, high_value FROM user_tab_subpartitions WHERE table_name = 'table_name';
Alter statement for partition to move to nocompress:
SQL> ALTER TABLE MOVE PARTITION NOCOMPRESS TABLESPACE ;
Eensure that you have enough disk space within your tablespaces before running the ALTER statement.
Support of compressed tables will be in future releases of OGG, however, in current V10.4 and V11.1.1.x, the only option, if a "move nocompress" is not possible, is to comment the compressed table or exclude them from the Extract.
From V11.1.1.0.0, Oracle has enhanced the error handling part in BugDB 9425542, which gives meaningful error message on the compressed record before Extract abend. It will list out the table name, rowid, etc
Example :
ERROR OGG-01028 Record on table QATEST1.TAB1 with rowid AAM4EkAAEAACBguAAA from transaction 5.24.270123 (0x0005.018.00041f2b) is compressed. Compression is not supported.
However, due to bug 10063108, sometimes the error message on compressed tables are not entirely correct. This problem has been fixed in 11.1.1.0.3 and above
A table created as compressed will cause all of the DML’s to go into compressed blocks on disk. If the user does an "alter table nocompress", every DML that goes into the table AFTER that point in time will be uncompressed. The query for compression will return "nocompress" now, but the simple "alter" does not change the already existing compressed blocks on disk that were created before the "alter". So to capture the records from a table which was compressed we need to do the following
SQL> alter table
This will touch every single block on disk and will uncompress everything thereby causing OGG to work properly and not abend.
If there is even a single partition in a partitioned table that is compressed, it will cause an abend. Partition compression can be verified by getting the full DDL for the table by running the DBMS_METADATA.GET_DDL package. For table partitions that are compressed, run the below query and get the partition names & tablespace names.
SQL> SELECT partition_name, subpartition_name, tablespace_name, high_value FROM user_tab_subpartitions WHERE table_name = 'table_name';
Alter statement for partition to move to nocompress:
SQL> ALTER TABLE
Eensure that you have enough disk space within your tablespaces before running the ALTER statement.
Support of compressed tables will be in future releases of OGG, however, in current V10.4 and V11.1.1.x, the only option, if a "move nocompress" is not possible, is to comment the compressed table or exclude them from the Extract.
Saturday, September 18, 2010
A Useful Oracle 11g New Feature
Server Result Cache
* Enables query result to be cached in memory which can be used during future execution of a similar query by bypassing the regular processing thereby returning the results faster.
* Decreases the wait time for both physical and logical IO by directly fetching the results from the cached memory.
* Cached result set is completely shareable between the sessions and various statements as long as they share a common execution plan.
* Server result cache is the new component of SGA that caches results of queries and is managed by automatic memory management.
* New parameter RESULT_CACHE_MAX_SIZE is used to enable result cache by setting the maximum size of the cache.
* A new optimizer hint allows use of result cache at the query level.
Query execution without result cache hint.

Server Result Cache
Query execution without result cache hint - Oracle 11gQuery execution without result cache hint – Oracle 11g
Query execution with result cache hint.

Query execution with result cache hint - Oracle 11gQuery execution with result cache hint – Oracle 11g
Parameters related to Result Cache
RESULT_CACHE_MAX_RESULT : specifies the percentage of RESULT_CACHE_MAX_SIZE that any single result can use
RESULT_CACHE_MAX_SIZE : specifies the maximum amount of SGA memory (in bytes) that can be used by the Result Cache.
RESULT_CACHE_REMOTE_EXPIRATION : specifies the number of minutes that a result using a remote object is allowed to remain valid
RESULT_CACHE_MODE : specifies when a ResultCache operator is spliced into a query’s execution plan.
How to find result cache information:
V$RESULT_CACHE_STATISTICS
V$RESULT_CACHE_MEMORY
V$RESULT_CACHE_OBJECTS
V$RESULT_CACHE_DEPENDENCY
DBMS_RESULT_CACHE – PL/SQL API for result cache management:
Functions : Status – displays the current status of the result cache.
SELECT DBMS_RESULT_CACHE.status FROM dual;
STATUS
—————————————————–
ENABLED
Flush: remove all objects from the result cache and release memory.
I will cover some more features in next post . Keep reading
* Enables query result to be cached in memory which can be used during future execution of a similar query by bypassing the regular processing thereby returning the results faster.
* Decreases the wait time for both physical and logical IO by directly fetching the results from the cached memory.
* Cached result set is completely shareable between the sessions and various statements as long as they share a common execution plan.
* Server result cache is the new component of SGA that caches results of queries and is managed by automatic memory management.
* New parameter RESULT_CACHE_MAX_SIZE is used to enable result cache by setting the maximum size of the cache.
* A new optimizer hint allows use of result cache at the query level.
Query execution without result cache hint.

Server Result Cache
Query execution without result cache hint - Oracle 11gQuery execution without result cache hint – Oracle 11g
Query execution with result cache hint.
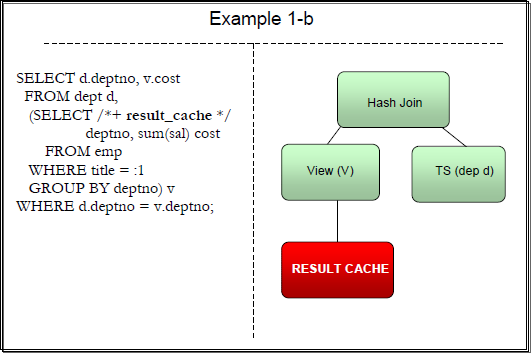
Query execution with result cache hint - Oracle 11gQuery execution with result cache hint – Oracle 11g
Parameters related to Result Cache
RESULT_CACHE_MAX_RESULT : specifies the percentage of RESULT_CACHE_MAX_SIZE that any single result can use
RESULT_CACHE_MAX_SIZE : specifies the maximum amount of SGA memory (in bytes) that can be used by the Result Cache.
RESULT_CACHE_REMOTE_EXPIRATION : specifies the number of minutes that a result using a remote object is allowed to remain valid
RESULT_CACHE_MODE : specifies when a ResultCache operator is spliced into a query’s execution plan.
How to find result cache information:
V$RESULT_CACHE_STATISTICS
V$RESULT_CACHE_MEMORY
V$RESULT_CACHE_OBJECTS
V$RESULT_CACHE_DEPENDENCY
DBMS_RESULT_CACHE – PL/SQL API for result cache management:
Functions : Status – displays the current status of the result cache.
SELECT DBMS_RESULT_CACHE.status FROM dual;
STATUS
—————————————————–
ENABLED
Flush: remove all objects from the result cache and release memory.
I will cover some more features in next post . Keep reading
Tuesday, August 10, 2010
Oracle WebLogic Server Basic Concepts
Check out this SlideShare Presentation:
Oracle WebLogic Server Basic Concepts
View more presentations from jambay.
Sunday, August 1, 2010
Oracle GoldenGate - Positioning a Read of Trail Files or Oracle Redo Log
Positioning in Extract / Replicat Trail and Log
In the event that there is ever a need to position an extract in the
Transaction Log (aka redo log), extract trail file or replicat trail file,
the following options can be used:
INFO EXTRACT, DETAIL
This will name your current redo log along with the RBA and sequence number and your extract trail name along with the RBA. RBA is the relative byte address of the record in the trail file at which the checkpoint was made
INFO EXTRACT, SHOWCH
Will show you your read checkpoint in the data source and write
checkpoint in the trail files.
Log Read Checkpoint File /orarac/oradata/racq/redo01.log ß- Oracle redo
2006-06-09 14:16:45 Thread 1, Seqno 47, RBA 68748800 info
Log Read Checkpoint File /orarac/oradata/racq/redo04.log
2006-06-09 14:16:19 Thread 2, Seqno 24, RBA 65657408
Current Checkpoint Detail:
Read Checkpoint #1
Oracle RAC Redo Log
Startup Checkpoint (starting position in data source):
Sequence #: 47
RBA: 68548112 ß– RBA offset of entry in redo log
Timestamp: 2006-06-09 13:37:51.000000
SCN: 0.8439720
Redo File: /orarac/oradata/racq/redo01.log
Recovery Checkpoint (position of oldest unprocessed transaction in
data source):
Sequence #: 47
RBA: 68748304
Timestamp: 2006-06-09 14:16:45.000000
SCN: 0.8440969
Redo File: /orarac/oradata/racq/redo01.log
Current Checkpoint (position of last record read in
the data source)
Write Checkpoint #1
GGS Log Trail ß– start of GG Trail Information
Current Checkpoint (current write position):
Sequence #: 2
RBA: 2142224 ß– RBA offset of entry in Trail file
Timestamp: 2006-06-09 14:16:50.567638
Extract Trail: ./dirdat/eh
Header:
Version = 2
Record Source = A
Type = 6
# Input Checkpoints = 2
# Output Checkpoints = 1
Once you have your checkpoint RBAs, you can use a few ggsci
commands to help you debug:
ADD EXTRACT
transaction log.
Some useful options are:
EXTTRAILSOURCE, specify the
fully qualified path name of the trail, for example c:\ggs\dirdat\aa.
BEGIN
Specifies a timestamp in the data source at which to begin
processing.
value is either:
□ NOW - the time at which the ADD EXTRACT command
is issued.
□ A date and time in the format of:
yyyy-mm-dd [hh:mi:[ss[.cccccc]]]
*** if you have a 4-node RAC cluster environment, use the
“THREADS 4” option to any command to which it applies.
EXTRBA
Specifies an RBA at which to start extracting. This can be used to
skip over a bad entry in a trail file.
ALTER EXTRACT
Allows changing the attributes of an extract file created by the ADD EXTRACT
command and allows the incrementing of an extract to the next file in the sequence.
***Always “STOP EXTRACT” before using this command.
You can use this command to make any changes using any of the options to the ADD EXTRACT command (above). So, for example, you can ALTER EXTRACT an extract file to begin at a specific RBA for skipping over an entry in the extract file.
Ex.: ALTER EXTRACT finance, EXTSEQNO 26, EXTRBA 338
You can change any of the attributes specified with the ADD EXTRACT command, except for the following:
□ Altering an Extract specified with the EXTTRAILSOURCE
option.
□ Altering the number of RAC threads specified with the THREADS
option.
SEND EXTRACT Allows you to send commands to a running extract process.
Some useful options are:
GETLAG shows lag time between the extract and the data source
LOGEND shows whether or not extract has processed all record in
the data source
ROLLOVER makes extract increment to the next file in the trail upon
startup
SHOWTRANS shows information about current transactions:
□ Process Checkpoint
□ Transaction ID
□ Extract Group Name
□ Redo Thread Number
□ Timestamp of first transaction of extract
□ System Change Number (SCN)
□ RBA and Redo Log Number
□ STATUS ( commit after it has been forced by FORCETRANS
(Pending Commit) or “running”)
In the event that there is ever a need to position an extract in the
Transaction Log (aka redo log), extract trail file or replicat trail file,
the following options can be used:
INFO EXTRACT
This will name your current redo log along with the RBA and sequence number and your extract trail name along with the RBA. RBA is the relative byte address of the record in the trail file at which the checkpoint was made
INFO EXTRACT, SHOWCH
Will show you your read checkpoint in the data source and write
checkpoint in the trail files.
Log Read Checkpoint File /orarac/oradata/racq/redo01.log ß- Oracle redo
2006-06-09 14:16:45 Thread 1, Seqno 47, RBA 68748800 info
Log Read Checkpoint File /orarac/oradata/racq/redo04.log
2006-06-09 14:16:19 Thread 2, Seqno 24, RBA 65657408
Current Checkpoint Detail:
Read Checkpoint #1
Oracle RAC Redo Log
Startup Checkpoint (starting position in data source):
Sequence #: 47
RBA: 68548112 ß– RBA offset of entry in redo log
Timestamp: 2006-06-09 13:37:51.000000
SCN: 0.8439720
Redo File: /orarac/oradata/racq/redo01.log
Recovery Checkpoint (position of oldest unprocessed transaction in
data source):
Sequence #: 47
RBA: 68748304
Timestamp: 2006-06-09 14:16:45.000000
SCN: 0.8440969
Redo File: /orarac/oradata/racq/redo01.log
Current Checkpoint (position of last record read in
the data source)
Write Checkpoint #1
GGS Log Trail ß– start of GG Trail Information
Current Checkpoint (current write position):
Sequence #: 2
RBA: 2142224 ß– RBA offset of entry in Trail file
Timestamp: 2006-06-09 14:16:50.567638
Extract Trail: ./dirdat/eh
Header:
Version = 2
Record Source = A
Type = 6
# Input Checkpoints = 2
# Output Checkpoints = 1
Once you have your checkpoint RBAs, you can use a few ggsci
commands to help you debug:
ADD EXTRACT
transaction log.
Some useful options are:
EXTTRAILSOURCE
fully qualified path name of the trail, for example c:\ggs\dirdat\aa.
BEGIN
Specifies a timestamp in the data source at which to begin
processing.
□ NOW - the time at which the ADD EXTRACT command
is issued.
□ A date and time in the format of:
yyyy-mm-dd [hh:mi:[ss[.cccccc]]]
*** if you have a 4-node RAC cluster environment, use the
“THREADS 4” option to any command to which it applies.
EXTRBA
Specifies an RBA at which to start extracting. This can be used to
skip over a bad entry in a trail file.
ALTER EXTRACT
Allows changing the attributes of an extract file created by the ADD EXTRACT
command and allows the incrementing of an extract to the next file in the sequence.
***Always “STOP EXTRACT
You can use this command to make any changes using any of the options to the ADD EXTRACT command (above). So, for example, you can ALTER EXTRACT an extract file to begin at a specific RBA for skipping over an entry in the extract file.
Ex.: ALTER EXTRACT finance, EXTSEQNO 26, EXTRBA 338
You can change any of the attributes specified with the ADD EXTRACT command, except for the following:
□ Altering an Extract specified with the EXTTRAILSOURCE
option.
□ Altering the number of RAC threads specified with the THREADS
option.
SEND EXTRACT Allows you to send commands to a running extract process.
Some useful options are:
GETLAG shows lag time between the extract and the data source
LOGEND shows whether or not extract has processed all record in
the data source
ROLLOVER makes extract increment to the next file in the trail upon
startup
SHOWTRANS shows information about current transactions:
□ Process Checkpoint
□ Transaction ID
□ Extract Group Name
□ Redo Thread Number
□ Timestamp of first transaction of extract
□ System Change Number (SCN)
□ RBA and Redo Log Number
□ STATUS ( commit after it has been forced by FORCETRANS
(Pending Commit) or “running”)
Subscribe to:
Posts (Atom)


